🤖💬 “Do GPTs Understand Language?” A Joyfully Serious Deep Dive (with Cornell vibes)🤖💬
Today's post inspired by an X post :

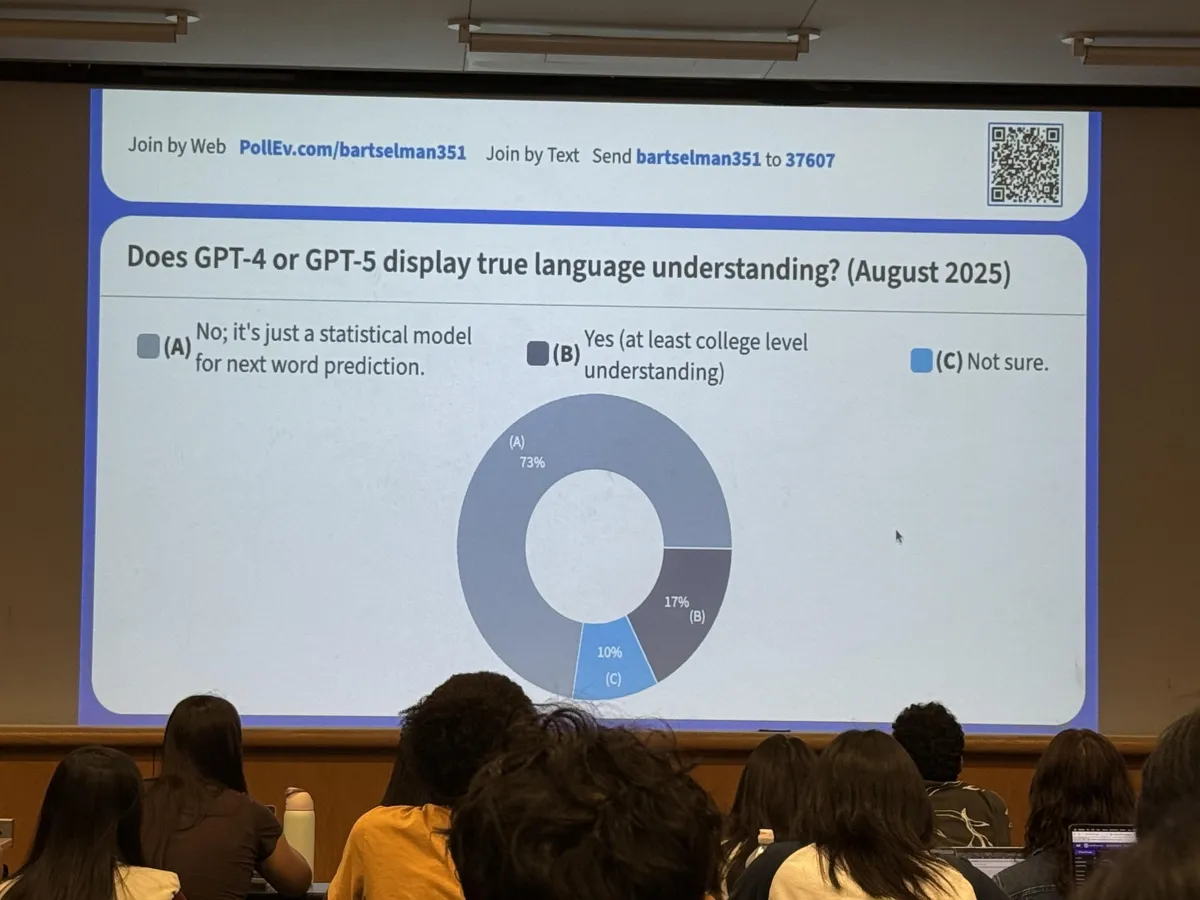
“wow 73% of Cornell CS students don’t believe GPT-5 has ‘college-level language understanding.’”
(Photo you shared: a live class poll showing 73% (A) “No,” 17% (B) “Yes,” 10% (C) “Not sure.”)
https://x.com/vvvincent_c/status/1962260421575950664
Okay… challenge accepted. Let’s steel-man both sides and go very deep—benchmarks, robotics, theory of mind, philosophy, hallucinations, compositionality, and more. Expect receipts 📚, wild questions ❓, and emojis everywhere ✨.
⚡ TL;DR
YES case says: modern LLMs show broad, exam-level competence; they chain thoughts, use tools, work with vision & action, and increasingly solve novel puzzles. That looks a lot like understanding. 🧠
NO case says: they’re still next-token predictors with no grounding; they hallucinate, break on compositional generalization, and can exploit benchmark shortcuts. That looks like statistical mimicry. 🎭
🤔 First, what do we mean by “understanding”?
Before arguing, define the target:
Semantic grasp: can the system map language to structured meaning and use it reliably across contexts?
Generalization: can it transfer knowledge to new combinations and new tasks?
Grounding: do symbols connect to the world (perception/action), not just other symbols?
Robustness: low hallucination, consistent reasoning, resilience to prompt phrasing.
Causality & reasoning: can it plan, explain, and use abstractions to achieve goals?
Hold those in mind as you weigh the evidence.
✅ The “YES—LLMs do understand (at least to a practical, college-level degree)” case
1) 📊 Broad academic performance that rivals or surpasses humans
GPT-4 demonstrated strong results across MMLU (a 57-subject “college-level” benchmark), the bar exam, and many other tests; these aren’t single tricks—they require cross-domain knowledge and reasoning. arXiv
The MMLU benchmark itself was designed to approximate college-level mastery across STEM, humanities, and social sciences—exactly what that Cornell poll asked about. arXiv
2) 🧮 From parroting to process: chain-of-thought & self-consistency
Prompting methods like Chain-of-Thought (CoT) and Self-Consistency significantly improve multi-step reasoning performance—suggesting the model isn’t just recalling answers but following procedures that generalize across tasks. arXiv+1
3) 🛠️ Tool use = functional understanding
Models can call calculators, search engines, knowledge bases, and APIs to extend themselves. Toolformer showed models can teach themselves when and how to invoke tools—deciding what they need to know and how to get it. That’s meta-cognition-ish. 🧰 arXiv+1OpenReview
The ReAct paradigm interleaves reasoning and acting (think: “plan, look up, revise, proceed”), reducing hallucinations on tasks like HotpotQA and boosting success on interactive environments. arXiv+1Google Research
4) 🌎🖼️🦾 Grounding through perception & action
RT-2 (a vision-language-action model) maps internet-scale knowledge to real-world robot control—following commands about novel objects and abstract goals (e.g., “pick the smallest item,” “choose an energy drink for someone tired”). This bridges symbols → actions, a classic step toward grounded understanding. arXivrobotics-transformer2.github.ioGoogle DeepMind
5) 🧩 Novel problem solving (beyond memorization)
Benchmarks like ARC-AGI aim to measure fluid intelligence—solving brand-new symbolic puzzles with minimal priors. Recent systems (e.g., OpenAI’s o-series) reported big jumps, which is hard to square with “mere training data recall.” 🧠✨ ARC Prize+2ARC Prize+2
6) 🧠 “Theory of mind” & social reasoning (contested, but notable)
Some studies argue that LLMs can pass classic Theory-of-Mind tests at levels comparable to children/adults, implying internal modeling of beliefs and perspectives. Even if mechanisms differ from humans, behaviorally they often succeed. 🎭➡️🧠 MIT Media Lab Courses
YES-side bottom line: When a system can (a) ace collegiate benchmarks, (b) explain its steps, (c) use tools, (d) perceive & act, and (e) tackle fresh puzzles—it looks less like a parrot and more like a competent language user with practical understanding.
❌ The “NO—It’s sophisticated mimicry/statistics” case
1) 🦜 The “Stochastic Parrots” argument
Foundational critique: LLMs stitch together statistical patterns from massive corpora without true meaning or intent; scale yields fluent text but not grounded semantics or truthfulness. This remains a central caution. arXiv
2) 🧪 Hallucinations are structural, not bugs
Surveys show hallucination is pervasive: models confidently produce false content under pressure (open-ended generation, domain shift). If they truly “understood,” why so many crisp fabrications? 📉 ScienceDirect
3) 🧱 Compositional generalization is still brittle
Humans effortlessly combine primitives (“jump,” “twice,” “after turning left”). LLMs often fail when tasks require systematic recombination outside their training distribution—e.g., CompWoB web tasks, SCAN-style splits, and newer compositional probes. Results: big drops from base tasks to composed ones. 🧩💥 OpenReviewarXiv+2arXiv+2
4) 🧪 Benchmark shortcuts & contamination
Plain MMLU was partly saturated; MMLU-Pro/Pro+ emerged to cut noise, add reasoning, and reduce guessability (10 options). If models were truly “college-level,” why the need for harder, contamination-resistant versions—and why do scores drop on them? 🎯 arXiv+2arXiv+2
5) 🧩 WinoGrande & coreference: still shaky
Even with massive scale, LLMs struggle with pronoun resolution that requires real-world knowledge and subtle semantics; re-evaluations and variants keep exposing brittleness. If “understanding” is there, it’s fragile. Communications of the ACM
6) 🏛️ Philosophy: symbols without grounding
Classic critiques like Searle’s Chinese Room and Harnad’s symbol grounding say text-only systems can manipulate symbols without meaning. Fluent outputs ≠ understanding. 🏺 arXivOpenAI
7) 🧪 “Theory of mind” may be mirages
Counter-analyses claim ToM “passes” often leak cues or reflect test familiarity; rearranging prompts can collapse performance, suggesting pattern matching rather than mental-state modeling. 🪞 web-archive.southampton.ac.uk
NO-side bottom line: If a system hallucinates, fails on strict compositional tests, and relies on benchmark quirks—then fluent text ≠ true understanding. It’s still impressive mimicry.
🧭 Reconciling the views (and what the Cornell poll really tells us)
Your photo shows 73% of a class skeptical—that’s instructive sentiment, not ground truth. The disagreement mirrors the field: behavioral competence vs philosophical grounding.
Reality may be graded: LLMs exhibit functional understanding in many contexts (exams, tools, robotics), yet lack robust, systematically compositional, fully grounded semantics everywhere. Both feelings can be right, depending on the bar you set.
🧪 What evidence would really move the needle?
If you’re on Team YES, you’d want to see more…
Out-of-distribution compositionality without prompt gymnastics (e.g., large consistent gains on ARC-AGI-2 & strong performance on tougher MMLU-Pro/+). arXiv+1
Grounded agents reliably using perception & action in messy real settings (not lab demos), scaling the spirit of RT-2. arXiv
If you’re on Team NO, you’d ask for…
Hallucination near-elimination under pressure. ScienceDirect
Strong compositional generalization on adversarial splits & multi-step tasks (clear wins on CompWoB-style suites). OpenReview
Demonstrations that withstand benchmark contamination and shortcut critiques (sustained improvements on MMLU-Pro/+). arXiv+1
❓ Rapid-fire questions to spark your inner methodologist
If a model can plan, use tools, and self-correct, at what point does “pattern matching” become competence? 🛠️🧭
Do we require embodiment (robots, sensors) for understanding, or can a model be grounded via simulations & tools alone? 🦾🖼️
If humans also approximate through heuristics & memory, is statistical ≠ semantic a false dichotomy? 👶🧠
Should we measure “college-level understanding” by benchmarks alone, or by long-horizon tasks (research assistance, experimental design, proofs)? 📑🔬
If ARC-AGI captures fluid reasoning, will consistent 85–90%+ across families finally settle this—or just move the goalposts? 🧩🏁 ARC Prize
🏁 My take (with humility!)
Today: LLMs demonstrate substantial, useful, and often college-level language competence in many contexts. The behaviors—tool use, multi-step reasoning, visual grounding, novel puzzle solving—are hard to dismiss.
But: Persistent hallucinations, brittle compositionality, and grounding gaps are real. Philosophically, “understanding” remains graded, not binary.
Thus: The Cornell split makes sense! If your bar is functional and behavioral, you’ll lean YES. If your bar is systematic, grounded, philosophically robust, you’ll lean NO.
📚 Sources you can explore (a starter pack)
GPT-4 Technical Report (capabilities across exams). arXiv
MMLU (college-level, 57 subjects). arXiv
Chain-of-Thought / Self-Consistency (reasoning boosts). arXiv+1
InstructGPT (RLHF) (alignment & truthfulness improvements). arXivNeurIPS Proceedings
ReAct (reasoning + acting; fewer hallucinations). arXiv+1
Toolformer (self-taught tool use). arXiv
RT-2 (vision-language-action grounding). arXiv
ARC-AGI & o-series progress (novel puzzle solving). ARC Prize+1
Hallucination survey (systematic issues). ScienceDirect
WinoGrande (coreference challenge). Communications of the ACM
Compositional brittleness (CompWoB & SCAN-style). OpenReviewarXiv
MMLU-Pro / Pro+ (harder, contamination-resistant). arXiv+1
Stochastic Parrots (statistical-mimicry critique). arXiv
ToM debate (claim & critique). MIT Media Lab Coursesweb-archive.southampton.ac.uk
🎉 Final thought
Whether you’re with the 73% skeptics or the 17% believers, the right move is the same: keep raising the bar. Push for grounded, compositional, contamination-resistant evaluations and real-world agency. If future systems clear those hurdles with consistency, even the hard-liners may switch teams. Until then—healthy skepticism + empirical curiosity = 🔥 combo.
